Using Reinforcement Learning
The main structure of CoopIHC is a multi-agent decision making model known as a Partially Observable Stochastic Game. Because of that, it is relatively easy to convert a CoopIHC Bundle to other decision-making models. In this example, we cover a transformation to a single-agent decision-making model—known as the Partially Observable Markov Decision Process (POMDP)— which we attempt to solve with an off-the-shelf, model-free, Deep Reinforcement Learning (DRL) algorithm. This will give us a trained policy, which we can then further use as any other policy for an agent.
The steps of this example are:
Define the Bundle as usual, where the policy of the agent to be trained has the correct action state but does not have a mechanism to select actions (e.g. random policy).
Wrap the bundle in a
TrainGymwrapper, making it compatible with the Gym API — a widely used standard in DRL research.Train the agent’s policy (i.e. attempt to solve the underlying POMDP). To do so, a machinery entirely specific to DRL and not CoopIHC is used. We will use Stable-Baselines 3 (SB3) to do so, which may add a few more constraints for step 2.
Apply the proper wrapper to make the trained policy compatible with CoopIHC.
A graphical representation of these steps is shown below.
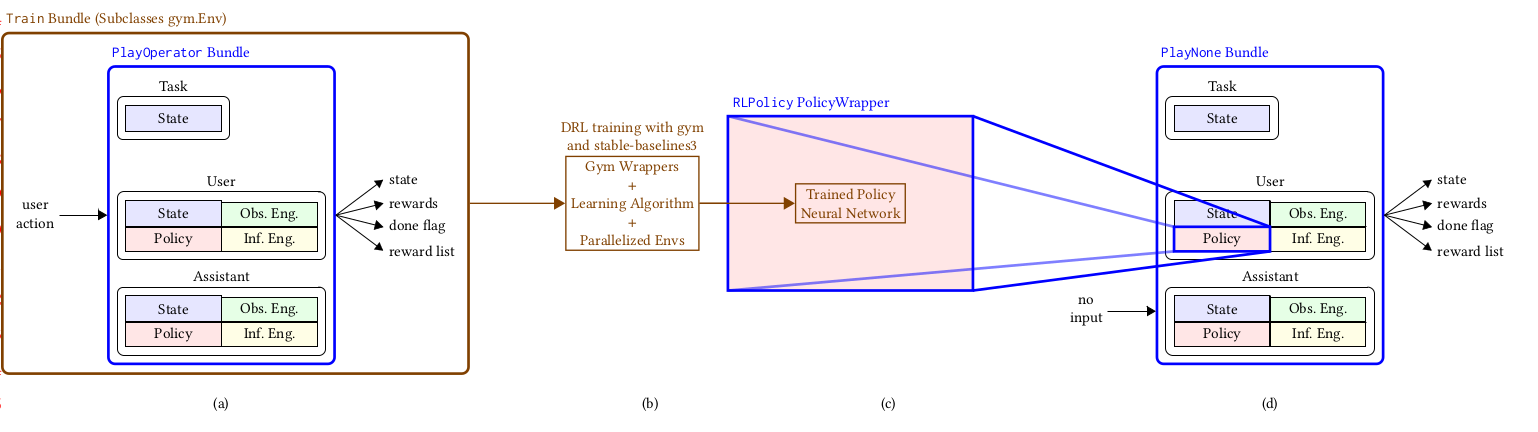
Fig. 3 A complete workflow using Deep RL, where a Bundle is wrapped as a Gym environment, an off-the-shelf learning algorithm is used, and the trained model is wrapped as a policy to be used in CoopIHC.
Note
You are not obliged to use SB3 nor Gym at all, but you may have to code your own set of wrappers if you choose not to do so. The existing code should however be relatively easy to adapt to accommodate other libraries.
Defining the Bundle
We use predefined objects of the pointing problem in CoopIHC-Zoo. The goal in this example is to formulate a user model that is close to real human behavior. To do so, we assume that human behavior is optimal and will seek to maximize rewards. As a result, we obtain the human-like policy by solving a POMDP where the learning algorithm selects actions and receives observations and rewards in return. We start by defining a bundle from the predefined components. This time however, the policy of the user agent is defined as the random policy with action set \(\lbrace -5,-4,\dots{}, 4, 5\). Note the use of the override (override_policy) mechanism.
1from coopihc.examples.simplepointing.envs import SimplePointingTask
2from coopihc.examples.simplepointing.users import CarefulPointer
3from coopihc.examples.simplepointing.assistants import ConstantCDGain
4
5
6task = SimplePointingTask(gridsize=31, number_of_targets=8)
7unitcdgain = ConstantCDGain(1)
8
9# The policy to be trained has the simple action set [-5,-4,-3,-2,-1,0,1,2,3,,4,5]
10action_state = State()
11action_state["action"] = discrete_array_element(low=-5, high=5)
12
13user = CarefulPointer(override_policy=(BasePolicy, {"action_state": action_state}))
14bundle = Bundle(task=task, user=user, assistant=unitcdgain, reset_go_to=1)
15observation = bundle.reset()
16
17# >>> print(observation)
18# ---------------- ----------- ------------------------- -------------------
19# game_info turn_index 1 CatSet(4) - int8
20# round_index 0 Numeric() - int64
21# task_state position 29 Numeric() - int64
22# targets [ 5 10 14 15 19 21 27 28] Numeric(8,) - int64
23# user_state goal 10 Numeric() - int64
24# user_action action -3 Numeric() - int64
25# assistant_action action [1] Numeric(1,) - int64
26# ---------------- ----------- ------------------------- -------------------
27
Note
Finding an optimal policy in this case is actually straightforward: the optimal reward is obtained by minimizing the number of steps, which implies that if the goal is out of reach, an action of \(\pm 5\) is selected, otherwise the remaining distance to the goal is selected.
Making a Bundle compatible with Gym
The Gym API expects a few attributes and methods to be defined. We provide a wrapper which makes the translation between CoopIHC and gym called TrainGym. We test that the environment is indeed Gym compatible with a function provided by stable baselines.
1rl_env = GymWrapper(
2 bundle,
3 train_user=True,
4 train_assistant=False,
5)
6
7obs = rl_env.reset()
8# >>> print(env.action_space)
9# Dict(user_action__action:Box([-5], [5], (1,), int64))
10# >>> print(env.observation_space)
11# Dict(game_info__turn_index:Discrete(4), game_info__round_index:Box([0], [9223372036854775807], (1,), int64), task_state__position:Box([0], [30], (1,), int64), task_state__targets:Box([0 0 0 0 0 0 0 0], [30 30 30 30 30 30 30 30], (8,), int64), user_state__goal:Box([0], [30], (1,), int64), user_action__action:Box([-5], [5], (1,), int64), assistant_action__action:Box([1], [1], (1,), int64))
12
13obs, reward, terminated_flag, truncated_flag, inf = rl_env.step(
14 {"user_action__action": 1}
15)
16
17# Use env_checker from stable_baselines3 to verify that the env adheres to the Gym API
18from stable_baselines3.common.env_checker import check_env
19
20check_env(rl_env, warn=False)
Note
TrainGym converts discrete spaces to be in \(\\mathcal{N}\) in line with Gym.
At this point, the environment is compatible with the Gym API, but we can not apply SB3 algorithms directly (check_env with warn = False raises no warnings, but does with warn = True). The reason is that CoopIHC returns dictionary spaces (gym.spaces.Dict) for actions , which is not supported by SB3 algorithms. We provide a simple action wrapper named TrainGym2SB3ActionWrapper that converts the actions to a “flattened space” (discrete actions are one-hot encoded to boxes).
1# sb3env = TrainGym2SB3ActionWrapper(env)
2# check_env(sb3env, warn=True)
It may be beneficial to write your own wrappers in many cases, especially considering it is usually pretty straightforward. The generic``TrainGym2SB3ActionWrapper`` wrapper converts discrete action spaces to unit boxes via a so-called one-hot encoding. The point of one-hot encoding is to make sure the metric information contained in the numeric representation does not influence learning (for example, for 3 actions A,B,C, if one were to code using e.g. A = 1, B = 2, C = 3, this could imply that A is closer to B than to C. Sometimes this needs to be avoided.) In the current example however, the actions represent distances to cover in either direction, and it is likely more efficient to convert the discrete space directly to a box by casting to a box (without one-hot encoding). In what follows, we will use hand-crafted wrappers.
Training an Agent
There are various tricks to making DRL training more efficient, see for example SB3’s tips and tricks. Usually, these require applying some extra wrappers. For example, for algorithms that work by finding the right parameters to Gaussians (e.g. PPO) it is recommended to normalize actions to \([-1,1]\).
Below, we apply some wrappers that filters out the relevant information out of the observation space and casts it to a continuous space (if not, SB3 will one-hot encode it automatically). Then, we apply a wrapper that casts the action to a continuous space and normalizes it.
1
2TEN_EPSILON64 = 10 * numpy.finfo(numpy.float64).eps
3
4
5class NormalizeActionWrapper(gym.ActionWrapper):
6 def __init__(self, env):
7 super().__init__(env)
8
9 self.action_space = gym.spaces.Box(
10 low=-1,
11 high=1,
12 shape=(1,),
13 dtype=numpy.float64,
14 )
15
16 def action(self, action):
17 return {
18 "user_action__action": int(
19 numpy.around(action * 11 / 2 - TEN_EPSILON64, decimals=0)
20 )
21 }
22
23 def reverse_action(self, action):
24 return numpy.array((action["user_action__action"] - 5.0) / 11.0 * 2).astype(
25 numpy.float64
26 )
27
28
29from gym.wrappers import FilterObservation, FlattenObservation
30
31# Apply Observation Wrapper
32modified_env = FlattenObservation(
33 FilterObservation(env, ("task_state__position", "user_state__goal"))
34)
35# Normalize actions with a custom wrapper
36modified_env = NormalizeActionWrapper(modified_env)
37# >>> print(modified_env.action_space)
38# Box(-1.0, 1.0, (1,), float64)
39
40
41# >>> print(modified_env.observation_space)
42# Box(0.0, 30.0, (2,), float32)
43
44
45check_env(modified_env, warn=True)
46# >>> modified_env.reset()
47# array([ 4., 23.], dtype=float32)
48
49# Check that modified_env and the bundle game state concord
50# >>> print(modified_env.unwrapped.bundle.game_state)
51# ---------------- ----------- ------------------------- -------------
52# game_info turn_index 1 CatSet(4)
53# round_index 0 Numeric()
54# task_state position 4 Numeric()
55# targets [ 2 7 8 19 20 21 23 25] Numeric(8,)
56# user_state goal 23 Numeric()
57# user_action action -5 Numeric()
58# assistant_action action [[1]] Numeric(1, 1)
59# ---------------- ----------- ------------------------- -------------
60
61for i in numpy.linspace(start=-1, stop=1, num=1000):
62 reset_state = modified_env.reset()
63 obs, _, _, _ = modified_env.step(i)
64 assert obs in modified_env.observation_space
65
66modified_env.step(
67 0.99
68) # 0.99 is cast to +5, multiplied by CD gain of 1 = + 5 increment
69
70# >>> modified_env.step(
71# ... 0.99
72# ... )
73# (array([ 9., 23.], dtype=float32), -1.0, False, \\infodict\\
74
75# >>> print(modified_env.unwrapped.bundle.game_state)
76# ---------------- ----------- ------------------------- -------------
77# game_info turn_index 1 CatSet(4)
78# round_index 1 Numeric()
79# task_state position 9 Numeric()
80# targets [ 2 7 8 19 20 21 23 25] Numeric(8,)
81# user_state goal 23 Numeric()
82# user_action action 5 Numeric()
83# assistant_action action [[1]] Numeric(1, 1)
84# ---------------- ----------- ------------------------- -------------
85
86
Not that everything is ready, we put all the relevant code into a function that, when called, will return an environment.
1def make_env():
2 def _init():
3 task = SimplePointingTask(gridsize=31, number_of_targets=8)
4 unitcdgain = ConstantCDGain(1)
5
6 action_state = State()
7 action_state["action"] = discrete_array_element(low=-5, high=5)
8
9 user = CarefulPointer(
10 override_policy=(BasePolicy, {"action_state": action_state})
11 )
12 bundle = Bundle(task=task, user=user, assistant=unitcdgain)
13 observation = bundle.reset(go_to=1)
14 env = TrainGym(
15 bundle,
16 train_user=True,
17 train_assistant=False,
18 )
19
20 modified_env = FlattenObservation(
21 FilterObservation(env, ("task_state__position", "user_state__goal"))
22 )
23 modified_env = NormalizeActionWrapper(modified_env)
24
25 return modified_env
26
27 return _init
28
29
We are now ready to train the policy. Here, we use PPO with 4 vectorized environments:
1if __name__ == "__main__":
2 env = SubprocVecEnv([make_env() for i in range(4)])
3 # to track rewards on tensorboard
4 from stable_baselines3.common.vec_env import VecMonitor
5 import os
6
7 os.makedirs(".tmp", exist_ok=True)
8 env = VecMonitor(env, filename=".tmp/log")
9 model = PPO("MlpPolicy", env, verbose=1, tensorboard_log="./tb/")
10 print("start training")
11 model.learn(total_timesteps=1e6)
12 model.save("saved_model")
A tensorboard excerpt shows that training is successful and rather quick, at 10 minutes of wall training time on a regular laptop.
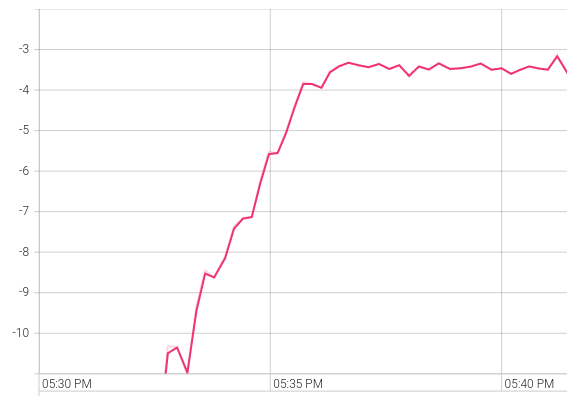
Fig. 4 Average rewards per episode plotted against wall time. Less than 10 minutes are needed to train this simple policy.
Loading the Trained Policy in CoopIHC
To load the trained policy in CoopIHC, a special policy object called RLPolicy exists. It works by passing the agent’s observation as input to the trained neural net and gathers the output action.
1model_path = "saved_model.zip"
2learning_algorithm = "PPO"
3
4
5class FilledFilterObservation(FilterObservation):
6 def __init__(self, env):
7 super().__init__(env, filter_keys=("position", "goal"))
8
9
10wrappers = {
11 "observation_wrappers": [FilledFilterObservation, FlattenObservation],
12 "action_wrappers": [NormalizeActionWrapper],
13}
14library = "stable_baselines3"
15
16trained_policy = RLPolicy(
17 action_state, model_path, learning_algorithm, env, wrappers, library
18)
The policy can be visualized, which confirms training was successful:
1distance_to_goal = []
2actions = []
3for i in range(1000):
4 bundle.reset(go_to=3)
5 obs = bundle.user.observation
6 distance_to_goal.append(
7 obs["user_state"]["goal"][0] - obs["task_state"]["position"][0]
8 )
9 action, reward = trained_policy.sample(observation=obs)
10 actions.append(action[0])
11
12import matplotlib.pyplot as plt
13
14fig = plt.figure()
15ax = fig.add_subplot(111)
16ax.plot(distance_to_goal, actions, "o", label="action")
17ax.set_xlabel("algebraic distance to goal (steps)")
18ax.set_ylabel("actions selected by the RLPolicy")
19ax.legend()
20plt.tight_layout()
21# plt.show()
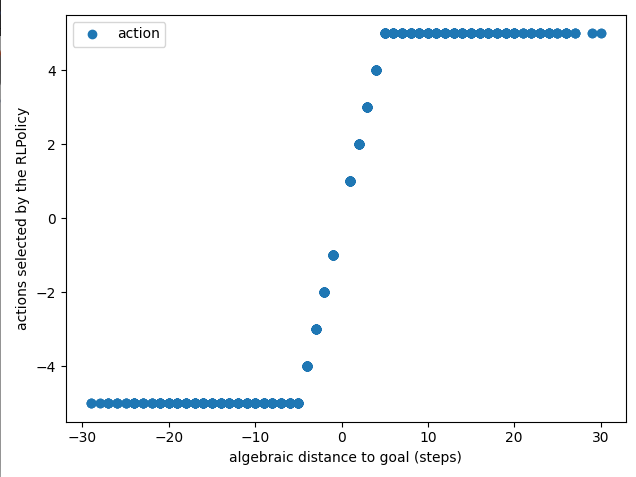
Fig. 5 Trained policy. As expected, the policy is the identity operator for the admissible actions, and otherwise it saturates at the edge admissible actions.
Finally, you can plug that policy back into the user and play with your bundle.
1task = SimplePointingTask(gridsize=31, number_of_targets=8)
2unitcdgain = ConstantCDGain(1)
3
4user = CarefulPointer(override_policy=(trained_policy, {}))
5bundle = Bundle(task=task, user=user, assistant=unitcdgain)
6
7bundle.reset()
8bundle.render("plotext")
9while True:
10 obs, rew, flag = bundle.step()
11 bundle.render("plotext")
12 if flag:
13 break